Research Questions
How should AI literacy, trustworthy visual AI, and DeepFake detection be taught together so that people learn both constructive use and robust verification?
For Academic Readers
This academic overview treats DeepFake and media forensics as part of a broader AI literacy agenda. It begins with constructive AI use and responsible deployment, then connects those foundations to representative papers, documented misinformation incidents, verification workflows, and source-backed teaching materials.
How should AI literacy, trustworthy visual AI, and DeepFake detection be taught together so that people learn both constructive use and robust verification?
Every highlighted case below is tied to a concrete public event, not a generic stock example.
The AI literacy course turns research concepts into reusable, evidence-backed modules for teaching, workshops, and cross-disciplinary collaboration.
This line sits between lab research, media verification, fact-checking, and public communication.

A viral clip claimed that Tel Aviv was under a meteor-like airstrike. TFC identified it as highly likely AI-generated. This is a good example of synthetic conflict footage that spreads because it looks visually dramatic and urgent.

The so-called “20 years ago Lai Ching-te speech” case is not only about generation. It is also about editing, reframing, and fabricated context. This is exactly why real-world media forensics cannot stop at a single detector score.

The fake audio of Taiwan’s president criticizing his predecessor shows why verification cannot stay video-only. Audio claims, reposted clips, and platform-level distortion create different failure modes from clean benchmark settings.

The “elderly duet” case shows how AI-generated clips can look harmless or uplifting while still training audiences to lower their guard. These cases matter because social sharing often rewards emotion before verification.
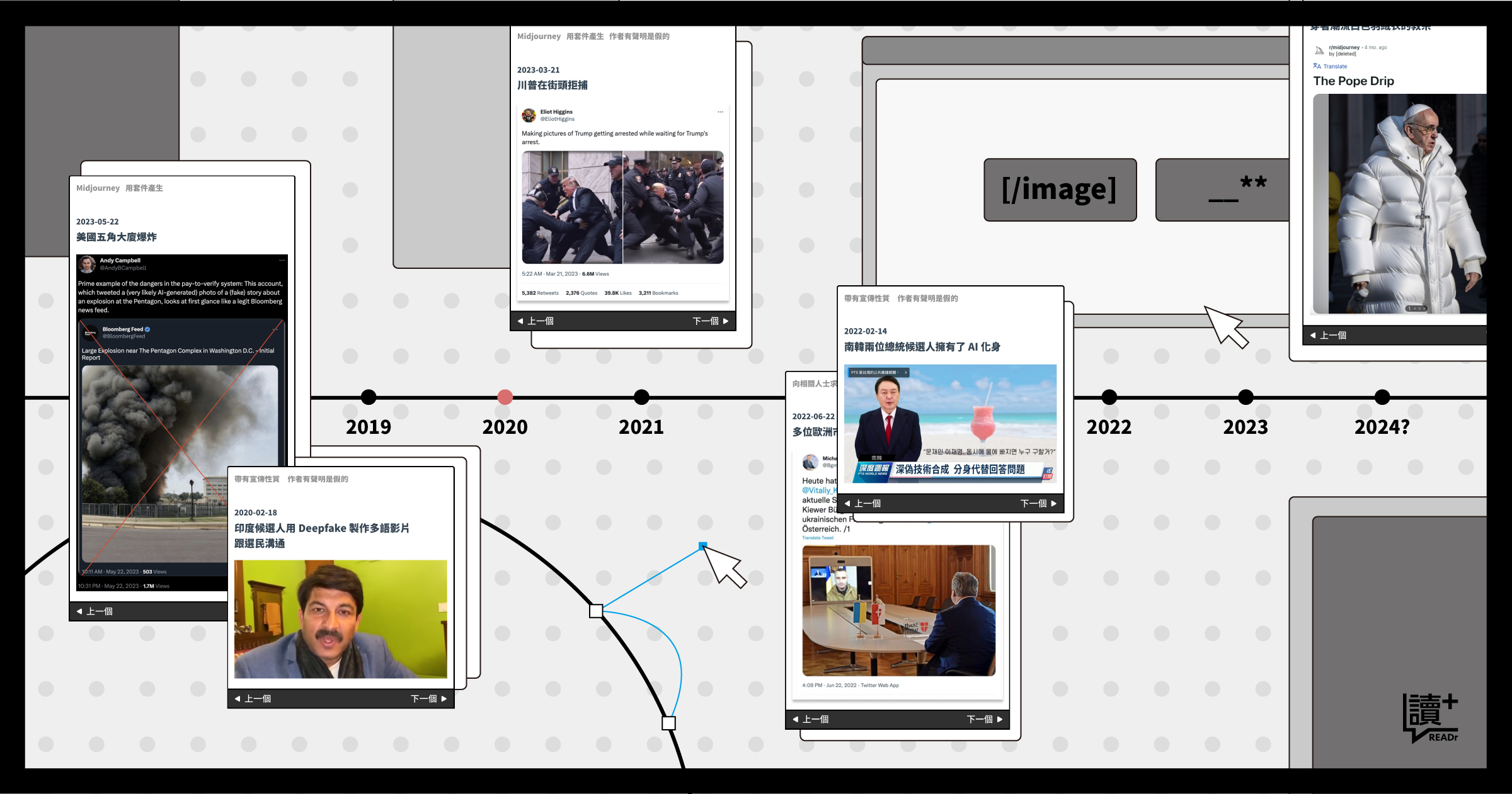
READr’s deepfake event archive is useful because it moves beyond one-off panic. It shows the range of cases, recurring manipulation patterns, and why some false media matters more than others.
FactLink’s AI verification guideline is worth showing alongside the cases because it turns the lab’s broader argument into newsroom-facing practice: suspicious imagery should be checked with workflow, not intuition.
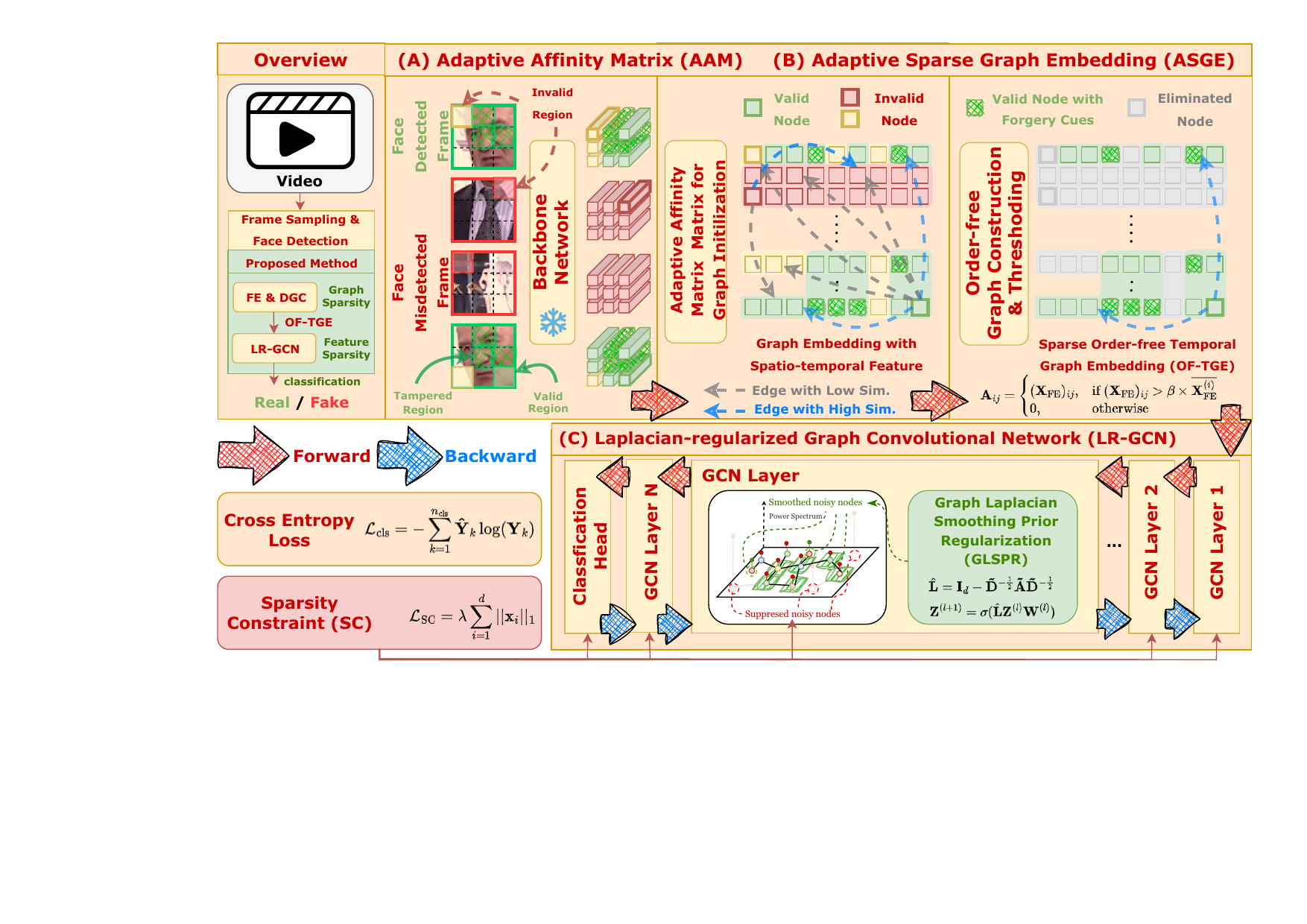
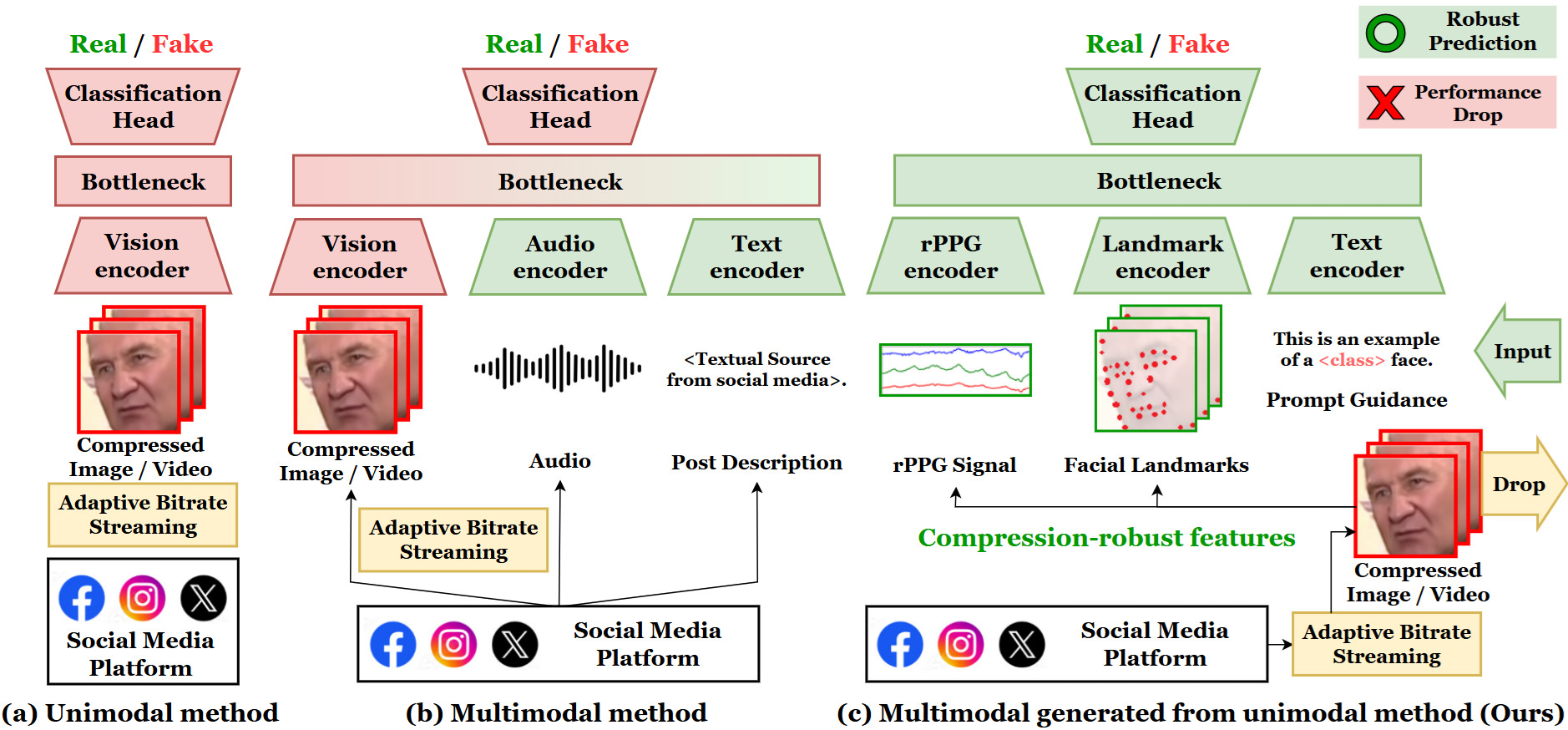
Explains synthetic media, forensic cues, and why detectors fail in realistic settings.
Shows practical search, source-checking, and evidence comparison workflows.
Uses source-backed examples instead of only abstract warnings.
Public-facing system entry for trying detector-assisted verification.
All external images on this page are tied to the corresponding original report or article above. They are used as cited event references, not as detached stock visuals.