
Technique 核心技術
-
Pairwise Learning
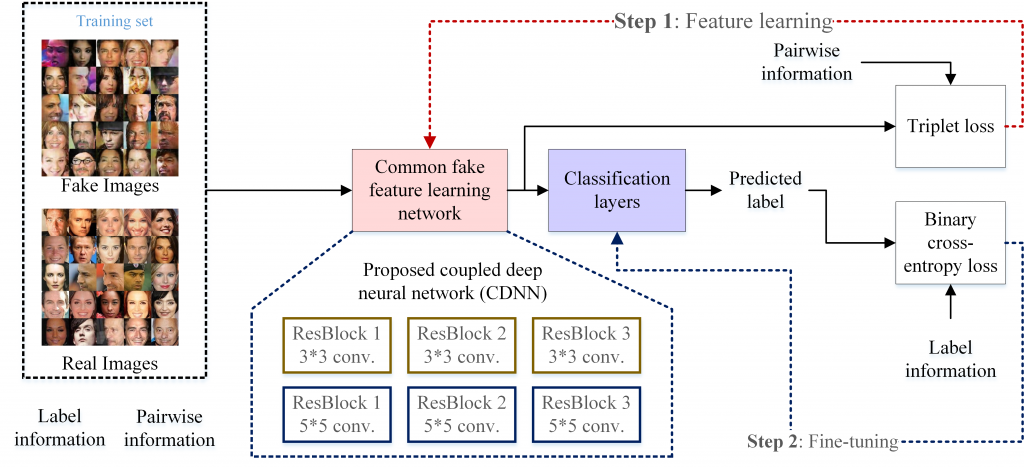
Since there are many GANs, it is hard to collect all training images from these GANs. Instead of learning the fake features for each GAN, we tend to learn the common fake features from the collected training images.
*Use contrastive loss or triplet loss to learn the common features from the generated images synthesized by several GANs !!
GAN可以產生很逼真影像,但如果要蒐集所有GAN的偽造影像太難了,而且GAN會一直更新,並不實際。透過學習數個GAN的共通偽造特徵,來類推未來GAN會產生的造假特徵,藉此提高本偽造影像偵測器的強健性 (Robustness)。
-
Two-Step Learning
First, we learn the common fake feature via the proposed pairwise learning.
Second, we adopt a small neural network as the classifier so that we can update both classifier and the common fake features.
兩階段學習:先學共同偽造特徵,再串接一個小的Network來訓練分類器。實驗證明效果比Joint training好!
-
Coupled Network
We adopt a two-stream network architecture consisting of the CNN with 3×3 and 5×5 kernels to capture the fake features locally and globally.
用一個雙路架構的CNN網路 (分別由3×3 and 5×5的Convolutional kernels組合而成) 來學習較局部性與全域性的偽造特徵。
Experimental Results
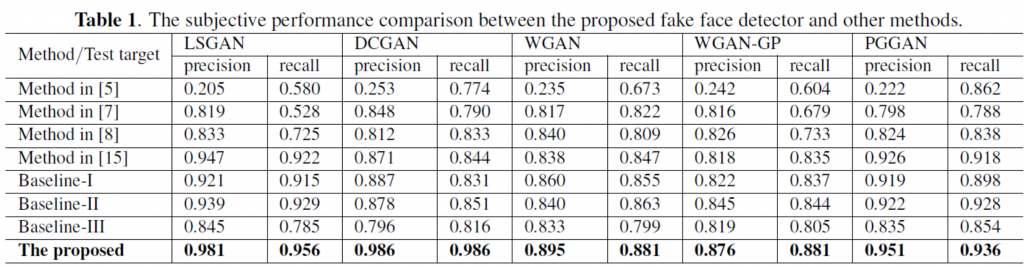
To verify the generalization of the proposed method, we remove the training images generated by one of the GANs as the training set. For example, if we remove the training image generated by PAGAN from the training set, then the trained fake face detector will not learn the fake feature from PGGAN. Afterward, the learned fake face detector is used to detect the test set consisting of the real images and fake images generated by PAGAN. Table I shows the performance comparison between the proposed fake face detector, other baseline methods, and methods in [7][8][15] in terms of accuracy, precision, and recall. The proposed method significantly outperforms other state-of-the-art methods due to the common fake features can be well captured by our CFF and CDNN architecture. It is also verified that the proposed method is more generalized and effective than others.
訓練過程中,從收集的六個GAN中去除其中一個GAN,並將訓練好的模型拿來測試該GAN藉此檢驗本方法是否可以推廣到未來其他的GAN。實驗結果證明本方法可以得到最佳的效果 (Precision / Recall rate)
Visualized Results

Moreover, the proposed model can be used to visualize the fake regions of the generated image by extracting the last convolutional layer and mapping the responses to the image domain. The visualized feature map for fake regions localization. (a) and (c) are the generated face images by PGGAN [1] and DCCAN [11] respectively. (b) and (d) are the localized fake regions for the fake faces of (a) and (b).
除了可以偵測影像本身是偽造還是真實影像之外,亦可透過Feature visualization engineering的方式來獲得人臉偽造區域資訊。
References
- Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen, “Progressive growing of gans for improved quality, stability, and variation,” arXiv preprint arXiv:1710.10196, 2017.
- Andrew Brock, Jeff Donahue, and Karen Simonyan,“Large scale gan training for high fidelity natural image synthesis,” arXiv preprint, arXiv:1809.11096, 2018.
- Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” arXiv preprint, 2017.
- “Ai can now create fake porn, making revenge porn even more complicated,” in http://theconversation.com/aican-now-create-fake-porn-making-revenge-porn-evenmore-complicated-92267, 2018.
- Hany Farid, “Image forgery detection,” IEEE Signal processing magazine, vol. 26, no. 2, pp. 16–25, 2009.
- Chih-Chung Hsu, Tzu-Yi Hung, Chia-Wen Lin, and Chiou-Ting Hsu, “Video forgery detection using correlation of noise residue,” in Proc. of IEEE Workshop on Multimedia Signal Processing, 170–174, 2008.
- Bolin Chen Huaxiao Mo and Weiqi Luo, “Fake faces identification via convolutional neural network,” in Proceedings of the ACM Workshop on Information Hiding and Multimedia Security, 2018, pp. 43–47.
- Marra, D. Gragnaniello, D. Cozzolino, and L. Verdoliva, “Detection of gan-generated fake images over social networks,” in Proc. of IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), pp. 384–389, April 2018,
- Franc¸ois Chollet, “Xception: Deep learning with depthwise separable convolutions,” arXiv preprint, pp. 1610–02357, 2017.
- Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “Generative adversarial nets,” in Proc. of Advances in Neural Information Processing Systems, 2014, pp. 2672–2680.
- Alec Radford, Luke Metz, and Soumith Chintala, “Unsupervised representation learning with deep convolutional generative adversarial networks,” arXiv preprint, arXiv:1511.06434, 2015.
- Martin Arjovsky, Soumith Chintala, and L´eon Bottou,“Wasserstein gan,” arXiv preprint, arXiv:1701.07875, 2017.
- Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, and Aaron C Courville, “Improved training of wasserstein gans,” in Proc. of Advances in Neural Information Processing Systems, pp. 5767–5777, 2017.
- Xudong Mao, Qing Li, Haoran Xie, Raymond YK Lau, Zhen Wang, and Stephen Paul Smolley, “Least squares generative adversarial networks,” in Proc. of IEEE International Conference on Computer Vision (ICCV), pp. 2813–2821, 2017.
- Chia-Yen Lee, Chih-Chung Hsu and Yi-Xiu Zhuang, “Learning to detect fake face images in the wild,” arXiv preprint, arXiv:1809.08754, 2018.
- Hadsell S. Chopra and Y. LeCun, “Learning a similarity metric discriminatively, with application to face verification,” in Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2005, vol. 1, pp. 539–546.
- Hoffer and N. Ailon, “Deep metric learning using triplet network,” in Proc. of International Workshop on Similarity-Based Pattern Recognition, pp. 84–92, 2015.
- Yann LeCun, Bernhard E Boser, John S Denker, Donnie Henderson, Richard E Howard, Wayne E Hubbard, and Lawrence D Jackel, “Handwritten digit recognition with a back-propagation network,” in Proc. of Advances in Neural Information Processing Systems, pp. 396–404, 1990.
- Wang Z.i Liu, P. Luo and X. Tang, “Deep learning face attributes in the wild,” in Proc. of International Conference on Computer Vision (ICCV), 2015.
- Ilya Sutskever, James Martens, George Dahl, and Geoffrey Hinton, “On the importance of initialization and momentum in deep learning,” in Proc. of International conference on machine learning, pp. 1139–1147, 2013.
- Laptev M. Oquab, L. Bottou and J. Sivic, “Is object localization for free?-weakly-supervised learning with convolutional neural networks,” in Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 685–694, 2015.
- Kaiming He, et al., “Deep residual learning for image recognition,” In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- Gao Huang, et al., “Densely connected convolutional networks,” In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR),
https://cchsu.info/wordpress/wp-content/uploads/2020/12/NPUSTLogo.svg_-300×165.png
medium
none
media_image-13820000
widget_media_image
WP_Widget_Media_Image
86297993-5cd8-443d-b7a0-771ea04e74af
tile
ACVLAB, Department of Management Information Systems,
National Pingtung University of Science and Technology
Chih-Chung Hsu and Yi-Xiu Zhuang
[Github]
text-13820001
widget_text
WP_Widget_Text
a8048a6a-c55b-49f3-9674-84c481d77c92
tile
Abstract
With the rapid growth of generative adversarial networks (GANs), a photo-realistic image can be easily generated from a low-dimensional random vector nowadays. However, the generated image can be used to synthesize several persons who may have a potential effect on society with radical contents. Considering that many techniques to produce a photo-realistic facial image based on different GANs are already available, collecting training images of all possible generative models is difficult; hence, the learning-based approach would not effectively detect a fake image generated using an excluded generative model. To overcome this shortcoming, we propose a two-step pairwise learning approach to learn common fake features over the training images generated by using different generative models. First, the triplet loss will be used to simulate the relation between fake and real images and utilized to learn the discriminative features to determine whether an image is real or fake. Then, we propose a novel coupled network to accurately capture local and global image features of the fake or real images. The experimental results demonstrate that the proposed method outperforms the baseline supervised learning methods for fake facial image detection.
現在深度學習可以輕易產生逼真照片,不當使用引來可能會很大問題,例如產生造假的FB或其他社群網站的照片假資料。雖然仔細看這些照片還是可能看到瑕疵,然而通常大家不會很仔細去檢查這些照片。本研究以毒攻毒,藉由深度學習來判斷這些生成的造假影像,來解決未來可能有大量偽造人臉影像流竄於社群網路上的問題。
tinymce
7807647685c6e36c97f719537536411
1557853159540
SiteOrigin_Widget_Editor_Widget
6df3cf7e-1bdf-413a-b469-ef02c48c866a
tile
sow-editor-13820002
widget_sow-editor
Technique 核心技術
-
Pairwise Learning
Since there are many GANs, it is hard to collect all training images from these GANs. Instead of learning the fake features for each GAN, we tend to learn the common fake features from the collected training images.
*Use contrastive loss or triplet loss to learn the common features from the generated images synthesized by several GANs !!
GAN可以產生很逼真影像,但如果要蒐集所有GAN的偽造影像太難了,而且GAN會一直更新,並不實際。透過學習數個GAN的共通偽造特徵,來類推未來GAN會產生的造假特徵,藉此提高本偽造影像偵測器的強健性 (Robustness)。
-
Two-Step Learning
First, we learn the common fake feature via the proposed pairwise learning.
Second, we adopt a small neural network as the classifier so that we can update both classifier and the common fake features.
兩階段學習:先學共同偽造特徵,再串接一個小的Network來訓練分類器。實驗證明效果比Joint training好!
-
Coupled Network
We adopt a two-stream network architecture consisting of the CNN with 3×3 and 5×5 kernels to capture the fake features locally and globally.
用一個雙路架構的CNN網路 (分別由3×3 and 5×5的Convolutional kernels組合而成) 來學習較局部性與全域性的偽造特徵。
tinymce
6649739635c6e3ad5e9eb8605915683
1550731464736
SiteOrigin_Widget_Editor_Widget
2ee1215a-0e4d-4904-b7c2-ec162f1b4583
tile
sow-editor-13820003
widget_sow-editor
Experimental Results
tinymce
18885882145c6e46e013d8a114340552
1609257571174
SiteOrigin_Widget_Editor_Widget
7804a2e2-bcfd-4888-82c7-dd15dca44ec8
tile
sow-editor-13820004
widget_sow-editor
To verify the generalization of the proposed method, we remove the training images generated by one of the GANs as the training set. For example, if we remove the training image generated by PAGAN from the training set, then the trained fake face detector will not learn the fake feature from PGGAN. Afterward, the learned fake face detector is used to detect the test set consisting of the real images and fake images generated by PAGAN. Table I shows the performance comparison between the proposed fake face detector, other baseline methods, and methods in [7][8][15] in terms of accuracy, precision, and recall. The proposed method significantly outperforms other state-of-the-art methods due to the common fake features can be well captured by our CFF and CDNN architecture. It is also verified that the proposed method is more generalized and effective than others.
訓練過程中,從收集的六個GAN中去除其中一個GAN,並將訓練好的模型拿來測試該GAN藉此檢驗本方法是否可以推廣到未來其他的GAN。實驗結果證明本方法可以得到最佳的效果 (Precision / Recall rate)
Visualized Results
Moreover, the proposed model can be used to visualize the fake regions of the generated image by extracting the last convolutional layer and mapping the responses to the image domain. The visualized feature map for fake regions localization. (a) and (c) are the generated face images by PGGAN [1] and DCCAN [11] respectively. (b) and (d) are the localized fake regions for the fake faces of (a) and (b).
除了可以偵測影像本身是偽造還是真實影像之外,亦可透過Feature visualization engineering的方式來獲得人臉偽造區域資訊。
References
- Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen, “Progressive growing of gans for improved quality, stability, and variation,” arXiv preprint arXiv:1710.10196, 2017.
- Andrew Brock, Jeff Donahue, and Karen Simonyan,“Large scale gan training for high fidelity natural image synthesis,” arXiv preprint, arXiv:1809.11096, 2018.
- Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” arXiv preprint, 2017.
- “Ai can now create fake porn, making revenge porn even more complicated,” in http://theconversation.com/aican-now-create-fake-porn-making-revenge-porn-evenmore-complicated-92267, 2018.
- Hany Farid, “Image forgery detection,” IEEE Signal processing magazine, vol. 26, no. 2, pp. 16–25, 2009.
- Chih-Chung Hsu, Tzu-Yi Hung, Chia-Wen Lin, and Chiou-Ting Hsu, “Video forgery detection using correlation of noise residue,” in Proc. of IEEE Workshop on Multimedia Signal Processing, 170–174, 2008.
- Bolin Chen Huaxiao Mo and Weiqi Luo, “Fake faces identification via convolutional neural network,” in Proceedings of the ACM Workshop on Information Hiding and Multimedia Security, 2018, pp. 43–47.
- Marra, D. Gragnaniello, D. Cozzolino, and L. Verdoliva, “Detection of gan-generated fake images over social networks,” in Proc. of IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), pp. 384–389, April 2018,
- Franc¸ois Chollet, “Xception: Deep learning with depthwise separable convolutions,” arXiv preprint, pp. 1610–02357, 2017.
- Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “Generative adversarial nets,” in Proc. of Advances in Neural Information Processing Systems, 2014, pp. 2672–2680.
- Alec Radford, Luke Metz, and Soumith Chintala, “Unsupervised representation learning with deep convolutional generative adversarial networks,” arXiv preprint, arXiv:1511.06434, 2015.
- Martin Arjovsky, Soumith Chintala, and L´eon Bottou,“Wasserstein gan,” arXiv preprint, arXiv:1701.07875, 2017.
- Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, and Aaron C Courville, “Improved training of wasserstein gans,” in Proc. of Advances in Neural Information Processing Systems, pp. 5767–5777, 2017.
- Xudong Mao, Qing Li, Haoran Xie, Raymond YK Lau, Zhen Wang, and Stephen Paul Smolley, “Least squares generative adversarial networks,” in Proc. of IEEE International Conference on Computer Vision (ICCV), pp. 2813–2821, 2017.
- Chia-Yen Lee, Chih-Chung Hsu and Yi-Xiu Zhuang, “Learning to detect fake face images in the wild,” arXiv preprint, arXiv:1809.08754, 2018.
- Hadsell S. Chopra and Y. LeCun, “Learning a similarity metric discriminatively, with application to face verification,” in Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2005, vol. 1, pp. 539–546.
- Hoffer and N. Ailon, “Deep metric learning using triplet network,” in Proc. of International Workshop on Similarity-Based Pattern Recognition, pp. 84–92, 2015.
- Yann LeCun, Bernhard E Boser, John S Denker, Donnie Henderson, Richard E Howard, Wayne E Hubbard, and Lawrence D Jackel, “Handwritten digit recognition with a back-propagation network,” in Proc. of Advances in Neural Information Processing Systems, pp. 396–404, 1990.
- Wang Z.i Liu, P. Luo and X. Tang, “Deep learning face attributes in the wild,” in Proc. of International Conference on Computer Vision (ICCV), 2015.
- Ilya Sutskever, James Martens, George Dahl, and Geoffrey Hinton, “On the importance of initialization and momentum in deep learning,” in Proc. of International conference on machine learning, pp. 1139–1147, 2013.
- Laptev M. Oquab, L. Bottou and J. Sivic, “Is object localization for free?-weakly-supervised learning with convolutional neural networks,” in Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 685–694, 2015.
- Kaiming He, et al., “Deep residual learning for image recognition,” In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- Gao Huang, et al., “Densely connected convolutional networks,” In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR),
tinymce
21177873825c7cdd3a07c9c234355188
1551687016703
sow-editor-13820005
widget_sow-editor
SiteOrigin_Widget_Editor_Widget
a69060ea-85ed-4940-ba8c-15cbaa8f9410
tile
tile
flex-start
tile
flex-start
right
tile
flex-start
right
tile
flex-start
right
5feb526b8aaad
SiteOrigin_Panels_Widgets_Layout
06d378c1-0411-4f32-841c-8444b20cf6e4
tile
siteorigin-panels-builder-13810000
widget_siteorigin-panels-builder