
語言:English | 繁體中文
研究願景
Advanced Computer Vision Lab — Assured Computer Vision: Lean, Autonomous, Broad-Spectrum
當 generative AI 逐步模糊真實與偽造媒體的邊界、自主系統對 vision 的可靠度要求愈來愈高,而 Earth observation 也進入高資料量的新階段時,真正能部署到現場的 visual intelligence 門檻自然跟著提高。ACVLab 的研究主軸可整理成四個彼此扣合的 pillars。
Assured Visual Intelligence 關心的是每一次 visual AI 輸出能不能被信任,無論是高壓縮條件下的 DeepFake detection、adversarial perturbation defense,或透過 proactive watermarking 進行 media authentication,核心都是讓 forensic、medical 與 regulatory 場景有足夠的 accountability。
Lean Visual Architectures 則從 computation abstraction 的不同層次重新設計系統:包含 exact attention 的 prefix-scan reformulation(ELSA)、略過 pixel decoding 的 bitstream-level forensics、在 ultra-low bit width 仍盡量守住 accuracy 的 adaptive quantization(QuantTune/FracQuant),以及 bandwidth-constrained satellites 上的 joint transmission-restoration,目標是把 latency、memory 與 energy cost 一起降下來。
Autonomous Visual Perception 把 vision 從 2D 影像推進到 3D physical space:material-aware scene reconstruction with hyperspectral unmixing、BEV adversarial defense for self-driving(BFDM)、能為下游 robotic pipelines 提供穩健特徵的 shadow / reflection removal(PhaSR、ReflexSplit),以及 uncertainty-aware 3D annotation for autonomous driving datasets。
Broad-Spectrum Scientific Sensing 則把感知能力推到可見光之外:vision-language prompts 驅動的 universal hyperspectral restoration(PromptHSI)、獲得未來科技獎肯定的 real-time CubeSat compressed sensing、透過 sparse spectral representations 進行的 hyperspectral pansharpening(S3RNet),以及能揭露 RGB 看不到操弄痕跡的 cross-spectral forgery detection。
這些 pillars 並不是各自獨立。Hyperspectral forensics 把 trust 和 spectral sensing 接起來,on-satellite real-time inference 把 efficiency 和 broad-spectrum data 接起來,BEV adversarial defense 則把 trust 和 embodied perception 接起來。對 ACVLab 而言,真正能落地的 visual intelligence,必須同時兼顧 trustworthy、efficient、embodied 與 perceptually complete。
研究支柱
- Autonomous Visual Perception: PhaSR、ReflexSplit、autonomous driving、tracking、embodied perception、3D reconstruction
- Assured Visual Intelligence: GRACEv2、UMCL、DDD-Net、DeepFake detection、proactive authentication、trustworthy media analysis
- Broad-Spectrum Scientific Sensing: PromptHSI、S3RNet、CubeSat compressed sensing、remote sensing、satellite imaging
- Lean Visual Architectures: ELSA、QuantTune、FracQuant、bitstream-level inference、CubeSat on-board processing、edge deployment
研究簡介: [PDF](最近更新:2024 年 10 月)

魯棒陰影移除
PhaSR: Generalized Image Shadow Removal with Physically Aligned Priors
已獲 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2026 接收。
在複雜且多光源的情境下,陰影移除容易受到物理照明先驗與學習特徵不一致的影響。PhaSR 結合 physically aligned normalization 與 geometry-semantic rectification,在超越單一光源假設的真實場景中仍能維持穩健表現。
研究方向。 自主視覺感知 / 魯棒場景恢復

真實世界反射分離
ReflexSplit: Single Image Reflection Separation via Layer Fusion-Separation
已獲 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2026 接收。
玻璃反射會造成高度非線性的圖層混合,讓既有分離模型在真實世界中容易失效。ReflexSplit 透過 dual-stream fusion-separation blocks 與 curriculum training,在合成與真實資料上都達到更穩健的反射分離能力。
研究方向。 自主視覺感知 / 魯棒場景恢復

高效率 AI 推論
ELSA: Exact Linear-Scan Attention for Fast and Memory-Light Vision Transformers
已獲 CVPR 2026 Findings Workshop 接收。
ELSA 將 exact softmax attention 重寫為 associative monoid 上的 prefix scan,在不需重新訓練的前提下實現更省記憶體的推論,並具備可證明的 FP32 穩定性。透過 Triton 與 CUDA C++ 實作,可同時提升資料中心與邊緣硬體上的部署性。
研究方向。 精實視覺架構 / 硬體無關推論
arXiv 預印本即將公開

量化友善部署
QuantTune: Optimizing Model Quantization with Adaptive Outlier-Driven Fine Tuning
發表於 IEEE International Conference on Multimedia Information Processing and Retrieval (MIPR) 2025。
QuantTune 聚焦於 Transformer 量化過程中的 outlier-driven dynamic range amplification,顯著降低低位元設定下的精度損失,且不需增加推論端的硬體複雜度,可跨 ViT、BERT 與 OPT 模型轉移。
研究方向。 精實視覺架構 / 量化感知部署
[arXiv] [IEEE Xplore]

通用高光譜復原
PromptHSI: Universal Hyperspectral Image Restoration with Vision-Language Modulated Frequency Adaptation
發表於 IEEE Transactions on Geoscience and Remote Sensing (TGRS), Early Access, Feb. 2026。
PromptHSI 是一個 all-in-one 的高光譜影像復原框架,結合 frequency-aware modulation 與 vision-language guided prompt learning,使單一模型即可同時處理雲遮蔽、模糊、雜訊與光譜缺失等多種遙測退化。
研究方向。 全頻譜科學感測 / 高光譜復原
[IEEE Xplore] [arXiv] [GitHub]

媒體安全與 DeepFake 魯棒性
Towards Robust DeepFake Detection under Unstable Face Sequences: Adaptive Sparse Graph Embedding with Order-Free Representation and Explicit Laplacian Spectral Prior
目前投稿至 IEEE Transactions on Information Forensics and Security (TIFS)。
GRACEv2 針對壓縮、遮擋、影格缺漏與順序擾動所造成的不穩定人臉序列設計,透過 order-free temporal graph embedding 與 explicit Laplacian spectral prior,在嚴苛真實條件下提升 DeepFake 偵測的穩健度。
研究方向。 可信視覺智慧 / 魯棒 DeepFake 偵測
[arXiv]

跨壓縮率 DeepFake 偵測
UMCL: Unimodal-Generated Multimodal Contrastive Learning for Cross-compression-rate Deepfake Detection
發表於 International Journal of Computer Vision (IJCV), Jan. 2026.
UMCL 從單一視覺輸入中合成對壓縮更穩健的多模態線索,包括 rPPG、時間 landmark 與語意嵌入,藉此提升跨壓縮條件下的 DeepFake 偵測能力,同時保留較具可解釋性的特徵關係。
研究方向。 可信視覺智慧 / 跨壓縮鑑識

新一代超解析度模型
DRCT: Saving Image Super-Resolution away from Information Bottleneck
Presented at IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2024, NTIRE Workshop [Oral].
Chih-Chung Hsu, Chia-Ming Lee, Yi-Shiuan Chou
研究方向。 精實視覺架構 / 高效率超解析度

CT 影像半監督偵測
A Closer Look at Spatial-Slice Features for COVID-19 Detection
Presented at IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2024, DEF-AI-MIA Workshop.
Chih-Chung Hsu, Chia-Ming Lee, Yang Fan Chiang, Yi-Shiuan Chou, Chih-Yu Jiang, Shen-Chieh Tai, Chi-Han Tsai
研究方向。 可信視覺智慧 / 醫療影像
[PDF] [arXiv] [GitHub] [Project Page]

高速高光譜壓縮感測
Real-Time Compressed Sensing for Joint Hyperspectral Image Transmission and Restoration for CubeSat
發表於 IEEE Transactions on Geoscience and Remote Sensing (TGRS)。
Future Technology Award(未來科技獎)
Chih-Chung Hsu, Chih-Yu Jian, Eng-Shen Tu, Chia-Ming Lee, Guan-Lin Chen
研究方向。 全頻譜科學感測 × 精實視覺架構
[IEEE Xplore] [GitHub]
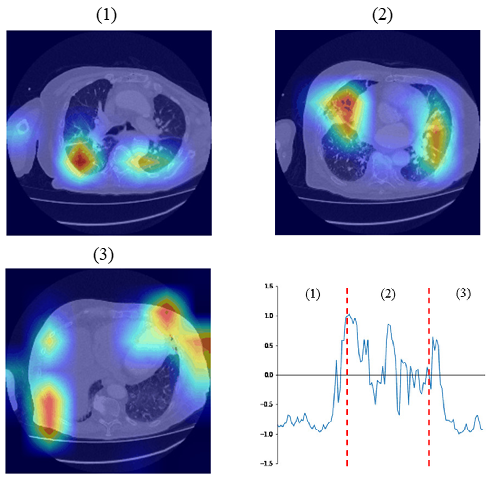
CT 影像中的 COVID-19 症狀偵測
精選競賽論文與成果
IEEE ECCV Workshop 2022[COV19D challenge 第 1 名]
IEEE ICCV Workshop 2021[COV19D challenge 第 3 名]
這系列模型專為 noisy、in-the-wild 的 CT 影像設計,在不同空間解析度與 slice resolution 下仍能維持穩健表現。
Social Media Prediction 的縱向建模
A Comprehensive Study of Spatiotemporal Feature Learning for Social Media Popularity Prediction
發表於 ACM Multimedia 2022。
C.C. Hsu, P.J. Tsai, T.C. Yeh, and X.U. Hou
我們將 social media popularity prediction 重新定義為 identity-preserving 的縱向任務,並分析 multimodal temporal features 如何提升長時間尺度下的預測穩定度。
[PDF]
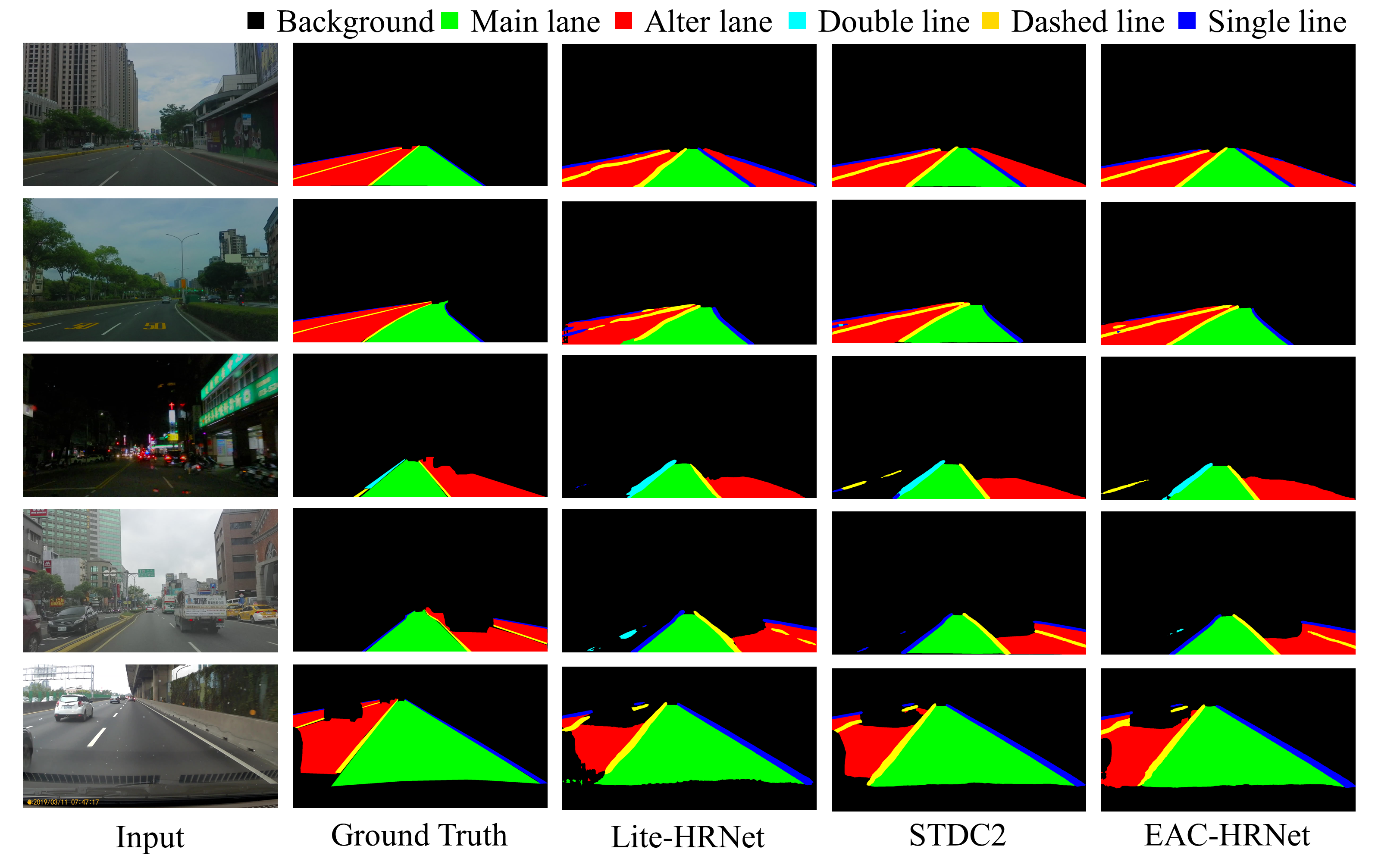
自駕場景語意分割
精選論文:聚焦穩健且高效率的場景理解
IEEE ICME Workshop 2022
Augmented-Training-Aware Bisenet for Real-Time Semantic Segmentation [PDF]
IEEE ICASSP 2022
DCSN: Deformable Convolutional Semantic Segmentation Neural Network for Non-Rigid Scenes [PDF]
這些工作聚焦於自駕場景中的即時語意理解,在 robustness 與 low-compute deployment 之間取得平衡。

偽造影像 / 影片(DeepFake)偵測
精選論文與延伸推廣
IEEE ICIP 2019 and Applied Sciences
Detecting Generated Image Based on Coupled Network with Two-Step Pairwise Learning
IEEE IS3C 2018
Learning to Detect Fake Face Images in the Wild
[Project] [PDF] [GitHub] [Online Demo]
偽造 / 造假照片偵測,聚焦於可信媒體分析與打擊假照片、假新聞。
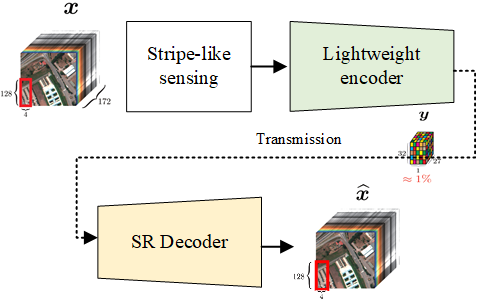
高光譜影像的深度壓縮感測
精選論文:聚焦高效率衛星感測
IEEE Transactions on Geoscience and Remote Sensing
DCSN: Deep Compressed Sensing Network for Efficient Hyperspectral Data Transmission of Miniaturized Satellite [PDF]
CVGIP 2020
Deep Joint Compression and Super-Resolution Low-Rank Network for Fast Hyperspectral Data Transmission
聚焦高光譜 / 多光譜影像的超解析度與壓縮感測,支援更高效率的衛星資料傳輸與復原。

以視覺資訊進行自駕車決策
精選研究:聚焦穩健的視覺決策
Multimedia Tools and Applications
Deep Learning-based Vehicle Trajectory Prediction based on Generative Adversarial Network for Autonomous Driving Applications
IEEE ICCE-TW 2020
Learning to Predict Risky Driving Behaviors for Autonomous Driving
[Large-Scale Vehicle Collision Dataset @ TW] [Link]
聚焦自駕車視覺系統中的危險駕駛行為預測,以及台灣道路資料庫的建置與分析。

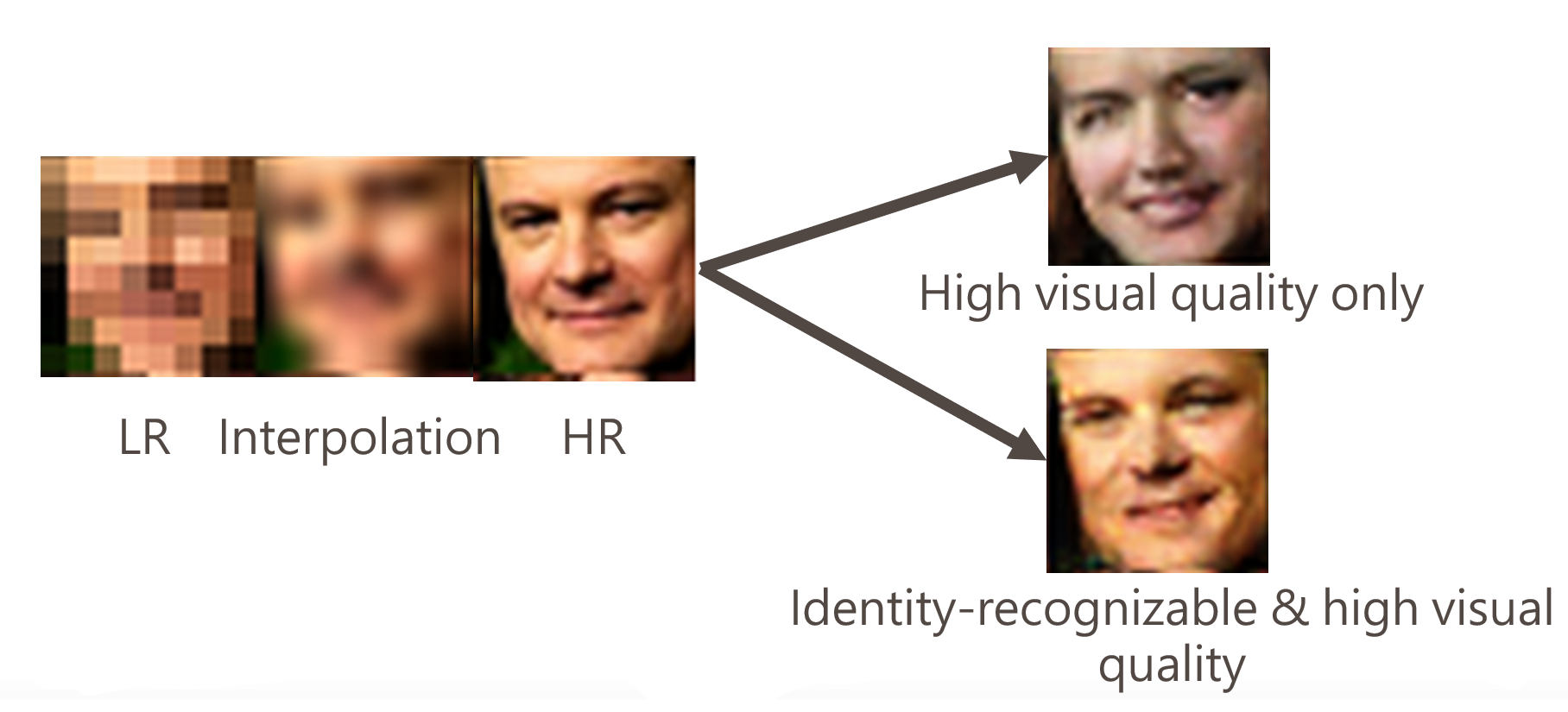

去方塊效應與超解析度
Learning-Based Joint Super-Resolution and Deblocking for a Highly Compressed Image
發表於 TMM 2015,並於 MMSP 2013 發表。
MMSP 2013 Top 10% Paper Award
[Project Page] [PDF] [Matlab Source Code (32-bit only)]
同時去除區塊效應並提高解析度,讓放大後的影像維持清晰。
具紋理視訊的超解析度
Temporally Coherent Super-Resolution of Textured Video via Dynamic Texture Synthesis
發表於 IEEE Transactions on Image Processing (TIP),並於 MMSP 2014 發表。
[Project Page] [PDF] [Matlab Code]
提供動態紋理視訊的超解析度技術,改善放大後的細節與時間一致性。

影像重定向品質評估
Objective Quality Assessment for Image Retargeting Based on Perceptual Geometric Distortion and Information Loss
發表於 IEEE Journal of Selected Topics in Signal Processing,並於 VCIP 2013 發表。
[Project Page] [PDF] [Matlab Code]
評估影像濃縮技術的品質,量化幾何失真與資訊流失。
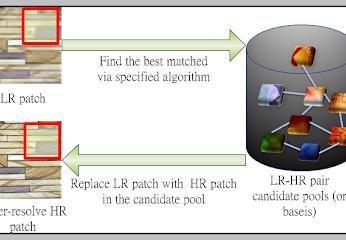
影像超解析度
Image Super-Resolution via Feature-Based Affine Transform
發表於 MMSP 2011。
[Project Page] [PDF] [Executable Code (Matlab)]
說明。 本頁提供以 NLM 為例的實作版本,示範所提出方法的使用方式。
這項影像超解析度方法著重於擴充資料庫中的樣態,提升放大後的重建效果。

人臉超解析度
Face Hallucination Using Bayesian Global Estimation and Local Basis Selection
發表於 MMSP 2010。
[Project Page] [PDF] [Matlab Code & Database]
人臉超解析度放大,從極低解析度人臉影像重建出較清晰的人臉結果。
視訊鑑識
Video Forgery Detection Using the Correlation of Noise Residue
發表於 MMSP 2008。
引用次數 > 100
[PDF] [Matlab Code] [Database]
視訊鑑識技術,聚焦於影片偽造偵測與可信媒體分析。

影像認證與竄改定位
Image Authentication and Tampering Localization Based on Watermark Embedding in the Wavelet Domain
發表於 Optical Engineering。
[PDF] [Source Code]
將浮水印藏入影像中,並可耐受不同攻擊以進行影像認證與竄改定位。