
Research Direction: Efficient AI / Hardware-Agnostic Inference
Authors: Chih-Chung Hsu, Xin-Di Ma, Wo-Ting Liao, and Chia-Ming Lee
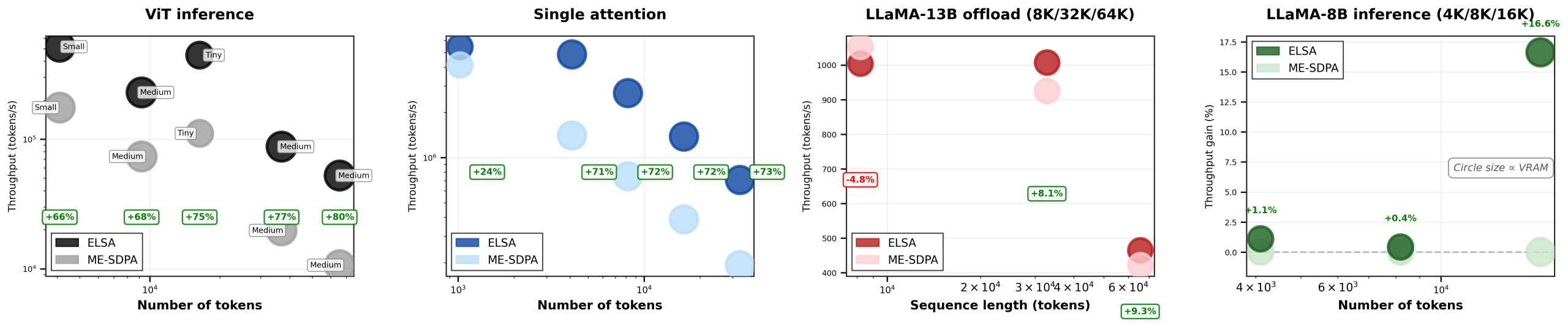
ELSA reformulates exact softmax attention as a prefix-scan problem over an associative monoid, enabling O(n) extra memory and O(log n) parallel depth without changing the operator or retraining the model. Unlike many acceleration schemes that depend heavily on fused Tensor Core kernels or approximate semantics, ELSA is designed to remain deployable across both server-class and edge hardware.
Implemented in Triton and CUDA C++, ELSA improves FP32 inference latency on high-resolution ViT inference and long-context LLM workloads while maintaining exact softmax behavior with a provable FP32 relative error bound. This work reflects our lab’s broader focus on making modern vision and multimodal AI both trustworthy and deployable in real-world systems.
- Key idea: exact linear-scan attention without retraining
- Target use cases: scientific imaging, edge AI, long-context inference, and hardware-diverse deployment
- Status: Accepted to the CVPR 2026 Findings Workshop
ArXiv link will be added once it is publicly available.